An IT Leaders Guide to Technology in Manufacturing
From data engineering and cloud migration, to legacy modernisation, AI and machine learning.

Note: None of this content was generated by ChatGPT. Only humans.
Introduction
Driven by emerging technologies and digital transformation initiatives, manufacturers face pressure to modernise their IT landscapes. Legacy systems built up over decades must now rapidly integrate with advanced automation, analytics and smart capabilities. For IT leaders, this represents both significant opportunities and challenges.
With research showing that 68% of manufacturing CEOs are increasing technology investments this year alone. Most have only digitised up to 10% of processes, with significant room for modernisation remaining. The focus is on automation, cybersecurity, and AI/ML, with many organisations planning to replace up to 75% of processes within two years.
Traditionally, manufacturers relied on rigid, siloed technology built for stable environments. To remain competitive in today’s industry landscape, IT leaders must now cultivate responsive, data-driven systems that enable people to derive insights from volumes of operational data. The goal is managing complexity while creating more value through agile production and processes.
This guide examines four critical technology areas for manufacturers: data, legacy, cloud and AI. Each section provides a comprehensive overview of each technology, including the relevant approaches to getting started and real-world case studies of organisations who have leveraged this technology to drive value.
- Introduction
- Data
- Key Considerations
- 1 - Where should you put your data?
- 2 - What processes should sit over your data?
- 3 - How will you visualise your data?
- Approach to Delivering Data Projects: 9 Steps
- Example Case Studies
- Cloud
- Approaches to Cloud Adoption
- Approach 1: Rehost
- Approach 2: Replatform
- Approach 3: Rearchitecture
- Example Case Studies
- Legacy
- Risks of Legacy Systems
- Options for Replacing Legacy Systems
- Option 1: Vanilla
- Option 2: Bespoke
- Option 3: Hybrid
- Approaches to Modernising Legacy Systems
- Approach 1: Rehost
- Approach 2: Refactor
- Approach 3: Rebuild
- Example Case Studies
- AI and Machine Learning
- How to Get Started
- Data Types
- Data Outputs
- Model Selection
- Approaches to Leveraging AI and Machine Learning
- Approach 1: Cloud Services
- Approach 2: Defining Your Own Model
- Example Case Studies
- Download
Data
Data is at the core of many decisions that organisations make. In manufacturing, good data helps organisations optimise production processes, improve product quality, enhance supply chain management and, ultimately, drive better decision making. Rich sources of aggregated data help organisations gain better insights across operations — from customers and production processes to finance and logistics.
A key struggle is consolidating and aggregating data sources. Most manufacturers process data across a variety of systems. Due to the disparate nature of these systems, providing access to data can be challenging.
Another major challenge is ensuring the timely flow of clean, accurate data. Delays of latency in data movement can mean that insights are based on outdated information. Data quality issues like inaccuracy, duplication and inconsistency can hinder the effectiveness of insights.
Latency in data availability also limits the ability to respond quickly to problems. Manual data wrangling processes fail to keep pace with speeds of modern production, so leveraging data warehousing tools like Snowflake are important in ensuring access to well-structured data.
As the volume of data continues to grow with IoT devices and smart factories, these challenges will only intensify. But overcoming them can drive better insights and decision making. Developing strong data management foundations and analytics capabilities is key for manufacturers to thrive in the future.
In this section:
- Key considerations before beginning data projects
- Approaches to deliver data projects
- Example case studies
Key Considerations
Before your organisation begins aggregating and transforming data, it is first useful to consider the 3 preliminary steps involved in planning these data projects:
1. Where should you put your data?
2. What processes should sit over your data?
3. How will you visualise your data?
1 - Where should you put your data?
Determining the optimal architecture to store and organise data is a crucial first step for manufacturers. By assessing current data volumes, variety and velocity, organisations can identify the infrastructure needed to meet processing and storage needs.
While a relational database may suffice for highly transactional data from ERP or MES systems, if your organisation is dealing with large volumes of unstructured and multi-structured data from various sources, then a data lake or data warehouse can be advantageous. In cases where organisations might need to store both raw and processed data, data lakehouses are also beneficial. Below is a breakdown of these different storage options:
| Data Lake | Data Warehouse | Data Lakehouse | |
|---|---|---|---|
| What? | A large repository that stores raw, unstructured data in its native format. | A structured repository that is optimised for querying and analysis | Combines the capabilities of data lakes and data warehouses. |
| How? | Does not transform or process data. Instead, it stores vast amounts of raw data until it is needed for further analytics and visualisation. | Data is cleaned, processed and modelled so that it is optimised for querying and analysis. | Stores both raw and processed data to enable organisations to perform rapid analytics on massive datasets while also persisting the raw data for future reprocessing as needs change. |
| When? | Storing clickstream data, sensor data, social media data for future machine learning and advanced analytics. | Generating reports, dashboards and analytics on areas like sales, marketing and operations. | You need to analyse raw data on-the-fly but also want performance of structured data. |
| Technologies | Snowflake, Apache Spark | Snowflake, Databricks | Databricks, Apache Spark |

2 - What processes should sit over your data?
Once quality data is aggregated, manufacturers need to implement robust processes to govern its use and provide oversight. A key first step is establishing data ingestion protocols that map data sources and cleanse, validate and integrate the data through ETL (Extract, Transform, Load) or ELT pipelines (Extract, Load, Transform).
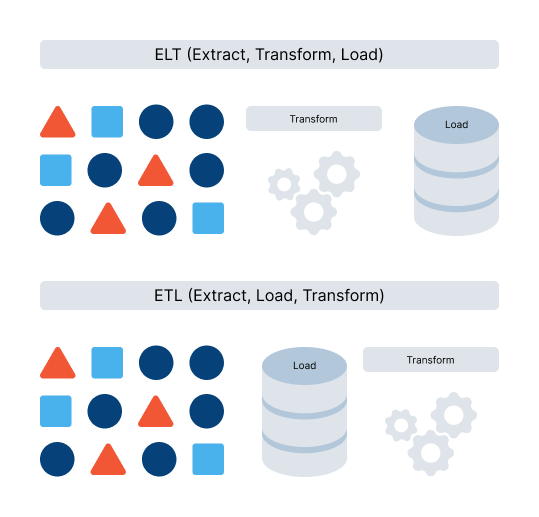
With quality data ingestion in place, ongoing monitoring should provide insights into data health KPIs like accuracy and completeness over time. Metadata catalogues are crucial for centrally recording definitions, business context and lineage. Master data management creates unified master datasets for products, suppliers, equipment and more.
Additionally, data quality rules and algorithms help detect anomalies, while comprehensive security and compliance policies are essential for protecting and governing data usage and integrity. With the right processes governing aggregated quality data, manufacturers can feel secure getting the insights needed to optimise operations.
3 - How will you visualise your data?
A question to ask your organisation here is “what does 'good' look like?”
What are the key metrics and KPIs that reflect performance and health across manufacturing operations?
What insights are needed to guide decisions around improving quality, efficiency, throughput and more?
If you're going into a boardroom, what strategic questions would you like to be able to answer from your data?
Defining these needs and aligning visualisations to critical business objectives is key to a successful data project.
Connect transformed datasets to analytics and visualisation tools like Power BI or Tableau. Build interactive dashboards to surface key findings and insights. Ensure accessibility across the organisation.

Enabling self-service access and updates allows cross-functional sharing of reports. Production monitoring integrates real-time sensor data alongside historical trends analysed using ML predictive analytics. With the right data foundation, processes, and reporting approach in place, manufacturers gain a substantial competitive advantage.
Dealing with this big data is an inherently complex challenge, so taking some time to first answer these questions can give your project some direction and ensure that you’re getting the most valuable insights.
Approach to Delivering Data Projects: 9 Steps
The following framework outlines the 9 steps required in orchestrating successful data projects:
1. Identifying data sources
2. Mapping integrations
3. Designing architectures
4. Selecting data storage
5. Validating data quality
6. Data integration
7. Data transformation
8. Data visualisation
9. Continuous improvement
1. Identify the sources of your data and current infrastructure landscape
For manufacturers, taking stock of current systems and data sources helps establish initiatives, whilst also identifying gaps that are preventing unified analytics.
Document where data resides across systems like ERP, MES, PLM and other core platforms. Catalogue details like database schemas, value formats and usage profiles. For unstructured data, this will mean assessing key file shares, logs and repositories.
Operational technology (OT) data is another key area where data is stored for manufacturing organisations, and encompasses automation systems, sensors and IoT devices producing time-series data. As with existing IT systems, it is important to identify source systems, data formats, collection needs and connectivity.
This system mapping will also highlight touchpoints between IT and OT, ultimately, revealing opportunities for aggregated views across platforms.
2. Map integration requirements based on key goals
Mapping integration requirements starts with identifying key goals and objectives. Ask things like:
- What insights and capabilities are needed to enhance performance in your organisation?
- What operational pain points or inefficiencies is your organisation trying to solve?
- What are the optimal data sources to address each pain point?
From there, determine the essential data integration needs to enable these goals. This process involves highlighting the vital reporting requirements, KPIs and dimensions that must be tracked over daily, monthly and yearly cycles.
Describe the analytics use cases that will leverage integrated data, whether descriptive, predictive or prescriptive. Outline where transactional systems need unified views for production monitoring or order tracking.
Documenting these needs frames the technical requirements for an integration solution. The capabilities directly link to driving impact, from increasing quality and output to reducing downtime and waste.
3. Design future state architecture and governance
Designing an optimal end-state architecture and governance model will ensure the security and longevity of your data projects. Central to this process is creating a clear data lifecycle that manages data from raw to transformed states, with retention policies based on use cases. Several areas need consideration here, including security, metadata management, data pipelines and storage infrastructure.
Comprehensive access policies for production data will also need development to ensure that the right employees and teams can access data when required. Part of this process should also include defining rules on data retention so that they align with storage costs and regulatory needs.
Above all, the architecture that you devise needs to be agile and modular enough to enable scaling up data streams and sources as automation and sensors expand. Automated data pipelines can be particularly useful here for providing resilience and orchestration as data volumes grow.
4. Select storage technology
How your data is stored is a fundamental decision in enterprise data projects, and one that impacts accessibility, performance, scalability and the analytics capabilities of your data. For this stage your organisation should evaluate data warehouse, lake and lakehouse technologies to determine the best option.
For time series data from industrial systems, Azure Synapse Analytics offers optimised storage and analysis capabilities. This tool ingests time series data into Azure Data Lake Storage and provides an SQL analytics engine to query the data.
Additional storage options like Snowflake data warehouses provide performant structured data storage optimised for BI. Data lakes like Azure Data Lake Store offer limitless retention of multi-structured data.
Lakehouses combine these capabilities, enabling both analytics and data science on governed datasets. This is particularly powerful in cases where manufacturers might want to apply machine learning to operational time series data. The governance of a data warehouse, combined with the scale of a lake, gives the flexibility to use time series data for both analytics and data science applications.
When deciding between these database/storage technologies, consider:
- Usage needs (What are the performance and access requirements of your applications?);
- Data types (What structures and schemas does your data conform to?); and
- Scale (What rates of data growth are anticipated?).
5. Validate data quality
Before transforming or analysing data, it is crucial to validate the quality of your data. Without proper validation, your organisation risks building data projects on a faulty foundation.
A systematic assessment should examine key dimensions like accuracy, completeness, conformity and duplication across datasets. Are values within expected ranges? Are certain records missing key attributes? Does data comply with formats and metadata requirements? Are there duplicate entries?
Leveraging profiling tools like Talend or SQL queries helps analyse data and quantify quality issues. These assessments illuminate how ‘dirty’ data might be compromising integrity.
With quality issues identified, cleansing is then required to align data to standards. Formatting, handling missing values, removing outliers, deduplication — these processes will eradicate the defects and restore fidelity.
High quality data is essential for everything that follows. Clean, complete, consistent data enables reliable analytics and decision-making. Taking the time to validate data quality early on also helps streamline additional transformations in the future.
6. Data integration
Data integration is crucial for manufacturers to prepare data for analytics and reporting. A key process is establishing protocols to ingest data from diverse sources across the manufacturing operations and unify it into a coherent dataset. This typically involves ETL or ELT pipelines.
First, data is extracted from the various source systems like production, inventory, maintenance, etc. Next, the data is cleansed, validated, combined, reshaped and processed as needed to create the desired unified dataset. Finally, the integrated dataset is loaded into the target database or data warehouse for analysis.
ETL and ELT pipelines automate what would be tedious manual data integration tasks for manufacturers. They provide a repeatable workflow to keep the unified dataset up to date. Cloud platforms like Azure Data Factory enable scalable, managed ETL/ELT services.
Key benefits for manufacturers include consolidated, contextualised data. The automation required for feeding data in helps improve productivity by replacing the need for manual data entry, ultimately, delivering accurate analysis-ready data.
7. Transform data
Transforming data allows organisations to modify the structure and format of raw data, ensuring it is in the optimal state to deliver value to your organisation. This involves shaping, conforming, aggregating and contextualising data to meet requirements. The priority is conforming raw data to the target schemas and models needed for systems. Tools like Databricks can map data from various sources into required structures effectively.
With properly structured data, the next task is enrichment. Joining discrete datasets into unified views removes data silos and provides complete pictures. This enables robust analytics and dashboards.
Incorporating external data elements also helps add perspective. For manufacturing organisations, this might be integrating real-time market demand data, competitor pricing information and supply chain disruption alerts into their production planning and decision-making processes.
The cumulative impact of all these transformations is increased utility and value of data. Unified, aggregated and contextualised data helps drive more impactful decisions for organisations. It is optimised to serve many downstream use cases. With thoughtful transformation, raw data becomes a strategic enterprise asset.
8. Develop visualisation
How you visualise your data will directly impact how insights are interpreted, shared and acted upon across your organisation.
Data visualisation tools like Power BI and Tableau BI are particularly useful here, with drag-and-drop simplicity to build dashboards drawing live data. These tools also provide the functionality for creating custom charts, graphs and layouts that are tailored to your organisation’s manufacturing KPIs and can help make insights easily interpretable. Interactive filters, similarly, allow users to drill down into granular views.
Tableau BI offers strong manufacturing-specific capabilities such as production metrics dashboards, asset utilisation tracking and quality management visualisations. The tool’s advanced mapping features also helps manufacturers visualise supply chain bottlenecks and sales by location.
Ultimately, intuitive reporting and visualisations should provide actionable insights to guide decisions. Identifying key users, needs and metrics aligned to business objectives steers the design of interactive reports.
9. Improving and aligning
Your project does not finish once a solution is in production. An ongoing action for organisations is to refine this solution based on user feedback and adoption. This also includes actions such as monitoring data pipeline health, quality and performance, as well as identifying new requirements and iterating on the architecture.
In addition to these areas, it is also important that your organisation continuously focuses on how well your project is aligning with overarching business goals and objectives. Maturing the capabilities of your data over time will ensure that you can further derive value from data assets.
Example Case Studies
A global engineering organisation
Leveraging big data analytics to optimise operational and maintenance costs by pinpointing product defects in real-time.
This organisation is a leading global supplier of technology and is, today, one of the largest suppliers in areas such as automotive components, industrial technology, consumer goods and building technology. Recently, the manufacturer has harnessed the power of big data analytics to enhance its approach to quality control within its production processes. Using data sourced from sensors embedded in production equipment and closely tracking products throughout the production journey, this organisation was able to pinpoint potential defects in real time and take corrective actions swiftly. These actions resulted in a significantly optimised operational and maintenance cost, with a 65% reduction in scrap cost and a 20% improvement in productivity.
At the core of this Big Data journey is a robust data analytics infrastructure, specially created to support the manufacturer’s innovative initiatives. Leveraging the latest analytics tools and platforms, this manufacturer employs methods such as natural language processing and deep learning, to process and interpret vast datasets with precision and speed.
Furthermore, this organisation has seamlessly integrated cloud computing into its data strategy, allowing for the efficient storage and processing of data. This cloud-based approach not only ensures scalability but also enables the manufacturer to expand its analytics capabilities as required.
An industrial mechanical seal manufacturer
Aggregating and consolidating large-scale product datasets across international sites for real-time visibility.
A leading industrial sealing solutions provider was looking to break down data silos and disparate systems to unlock analytics. The organisation’s vast product data was spread across outdated legacy systems and managed manually in spreadsheets. This stunted cross-functional visibility due to the lack of standards and integration. Moreover, manual processes couldn't scale to meet complex global data needs.
To break down these silos, a custom centralised quotation platform was developed. This new platform aggregated and unified product data from across the organisation into a single 360-degree view. ETL processes were implemented to ingest data from an array of sources and conform everything into a structured SQL database.
Data pre-processing was important here given that the organisation was dealing with several legacy systems, where data quality issues such as duplication were evident. Key steps such as rigorous data cleansing and transformation helped resolve quality issues during this migration. The organisation ensured data standards and integration through master data management, with Normalisation and indexing optimised query performance with these massive, unified datasets.
The organisation took a strict and disciplined approach when designing the schema for their system. Within their schema, there are specific sections or components dedicated exclusively to recording and describing different product combinations and the relationships between these products. This could include data about which products can be bundled together or how they relate to each other.
This ensures that data related to product combinations and relationships is not mixed or intertwined with data and processes related to order processing, CAD drawing generation or on-site installations, making the system more organised and easier to manage. This separation of concerns contributes to a more maintainable and efficient system design.
By performing advanced engineering calculations to identify suitable products on their behalf, the system now allows parts to be quoted by sales engineers with two years’ experience, where previously this would have required ten years’ experience in the industry. While this is a major benefit and requires aggregating data from a number of these different stores, there are also significant benefits that have been gained through data centralisation.
Previously, quotes were issued via a multitude of different routes. Each country might have subtly different processes, and data was stored in an array of locations. This made it very difficult to compare similar products and allow senior management to glean learning points. Now that this has been brought together under one centralised system, the manufacturer is now able to compare sales made in Australia to those issued in South Africa, for example, and interrogate this data to identify patterns. The overall effectiveness of the system resulted in a 72x faster quotation speed on non-standard component specifications.
Cloud
Cloud adoption continues to rise across industries, with 70% of organisations reporting more than half of their infrastructure exists in the cloud, while 49% say they’re actively moving more of their data to the cloud. Research shows that manufacturing organisations are seeing particular benefits from moving to the cloud, with 56% reporting improved productivity thanks to cloud adoption.
This increased productivity stems from the cloud’s ability to improve collaboration and provide on-demand access to computing resources. Research group Markets and Markets estimates that the cloud industry will have a Compound Annual Growth Rate of 16.3% over the next four years. This finding further highlights the value of cloud technology in the global market — both today and in the future.
For manufacturing, the cloud provides a solution to some of the unique challenges that this industry faces. Cloud-based infrastructure, for example, helps manufacturers scale resources up or down in line with their changing business requirements.
Take an automotives manufacturer as an example. This organisation may experience major fluctuations in demand based on the production schedules and needs of the automakers they supply. During peak periods when the automakers are ramping up new model production, demand for parts will surge. Cloud computing can be used to rapidly provision additional computer power, storage and network capacity to handle the spike in order volume. Then when demand starts to taper off again, they can scale back down to control costs. The cloud’s on-demand model gives them flexibility to align computing resources with their variable workload.
This technology is not without its challenges, however. Flexera's State of the Cloud survey shows that managing cloud spend (82%) and security (79%) are two main areas of concern for IT leaders, along with the ongoing skills gap.
It is essential to find an approach to cloud migration that will allow your organisation to meet the demands of your customers and stay competitive.
In this section:
- Approaches to adopting cloud technologies
- Example case studies
Approaches to Cloud Adoption
There are three popular approaches to consider for your cloud migration:
Approach 1: Rehost
Approach 2: Replatform
Approach 3: Rearchitecture
These options vary depending upon the current architecture of your applications and the goals of your organisation.
Approach 1: Rehost
This approach, also known as ‘lift and shift’, involves moving your existing data and applications from an on-site premise or data centre to a cloud server. No code needs to be recompiled or configured during this approach. For manufacturers, this could mean migrating ERP, MES or QA systems to cloud Virtual Machines (VMs) without the need for any change to existing codebases.
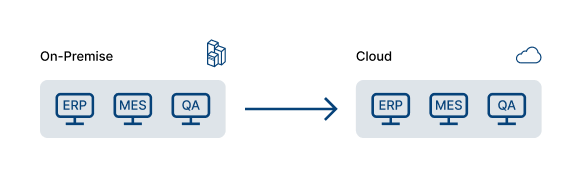
A virtual machine is an emulation of a computer system that runs its own operating system and functions like a separate computer. Once this infrastructure has been migrated to the cloud, your organisation will maintain control over these virtual machines just as it did on-premises.
Cloud migration provides a secure and robust infrastructure for your hosted environment. Organisations will be able to set up application gateways and will benefit from real-time monitoring of factors like dependency alerts and irregular request patterns.
Here are some more benefits of rehosting:
- Quick wins: Many organisations rehost applications because it can provide quick wins. By deploying your applications into a cloud environment, businesses can reduce costs and scale their operations.
- Cost reduction and scalability: Compared to hosting data on on-premises data centres, the cloud provides a more cost-effective solution as organisations do not need to maintain and upgrade physical infrastructure. Scalability is also easier when operating within the cloud, where organisations can easily adjust resources based on demand.
- Access to advanced cloud services: Rehosting applications in the cloud opens opportunities to leverage advanced cloud services and technologies. Organisations can access useful cloud resources without having to make big changes to their processes. This migration is also helpful when organisations want to move an application without the need for upgrading products.
However, there remain some factors that should be considered in this approach. For example, your software might still require a lot of maintenance and might not be robust enough to handle this migration. Businesses would then need to invest in refactoring or engineering their applications so that they can be successfully moved to the cloud. This approach can, therefore, provide a good short-term solution for businesses who are not yet looking to replatform or rebuild their applications.
Approach 2: Replatform
This approach involves making changes to existing applications to adapt the application for the cloud. The applications will retain a lot of their existing architecture, but minor changes are made to ensure that they can be successfully migrated to the cloud. These changes will then allow organisations to get the full benefits from this migration process. For manufacturing applications, this could mean modifying code to work with cloud databases or using managed services like AWS IoT for sensor data.
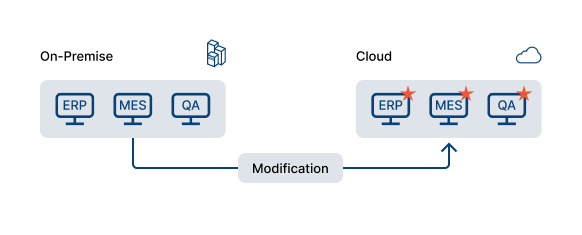
As with rehosting, this approach maintains the core architecture of applications. Organisations will also see similar benefits; they will save on costs required for maintaining infrastructure and software licences.
Here are some more benefits of replatforming:
- Flexibility: Replatforming provides organisations with the flexibility to choose the timing and approach of migrating their applications to the cloud. It allows them to prioritise critical systems or focus on specific business requirements before moving other applications.
- Utilisation of familiar resources: Organisations still retain some flexibility over their cloud migration strategy with this approach. Existing applications can be retired or migrated to the cloud in the future. The replatforming approach also enables developers to use resources they have experience with, such as legacy programming languages and existing frameworks.
- Access to cloud services: Another key benefit is that it gives organisations access to a range of beneficial cloud services. For example, Microsoft Azure offers Azure App Services that enables organisations to build enterprise-ready applications for any platform or device quickly and easily. After they are built, they can then be deployed on a scalable, reliable cloud infrastructure.
However, organisations should consider the extra complexities involved with refactoring applications for the cloud. Application code needs to be changed and then tested thoroughly to avoid a loss in functionality.
While these processes can be time consuming, the long-term cost savings and performance of applications still make this a viable choice for businesses migrating to the cloud.
Approach 3: Rearchitecture
With this approach, the architecture of your application is redesigned so that you can take full advantage of cloud computing. This approach redesigns applications to become cloud native. Usually, the application code needs to be restructured or optimised so that it can successfully move to the cloud.
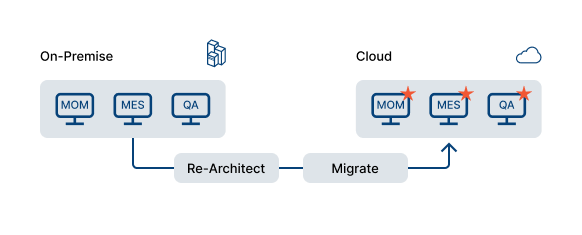
Manufacturers would rebuild core systems like MOM and MES using microservices, APIs and cloud storage.
Optimising the code of existing applications is a long and sometimes complex process. However, it will not alter the performance of the application. This consistency ensures business continuity throughout your cloud migration.
Here are some more benefits of rearchitecturing:
- Scalability and flexibility: By redesigning the architecture with cloud-native principles, such as microservices and containers, applications can scale seamlessly to manage varying workloads. This scalability allows organisations to accommodate increased user demand and traffic without compromising performance or incurring additional infrastructure costs.
- Agility and innovation: With these systems, organisations have access to advanced deployment tools that can optimise the agility of their enterprise architecture. Cloud-native environments simplify both the design and administration of traditionally complex infrastructures.
- Future-proofing: Cloud-native applications are better positioned to adapt to evolving business needs and technological advancements. For manufacturers undertaking large technology projects, rearchitecting core systems enables advanced analytics, IoT integration and edge computing capabilities not possible with legacy applications.
Organisations who have executed this approach and moved away from an on-premises infrastructure are now cloud native. These cloud-native applications are developed to take advantage of public cloud platforms.
This approach will, therefore, have the greatest impact on projects in the long-term. Businesses can easily scale up or down as needed and the added functionality of a cloud-native architecture ensures optimum performance of key business areas.
Example Case Studies
A global chemicals manufacturer
Leveraging Azure cloud technologies to consolidate and manage data transfer across systems
A leading chemicals manufacturer aimed to rebrand and update critical applications for two of its subsidiaries. A key challenge in this project was consolidating and managing data from the subsidiaries' unique ERP and CRM systems. To centralise and streamline data transfers, the organisation implemented Azure Data Factory. This cloud-based integration service pulled data from across their systems into a unified view.
With Azure Data Factory's cloud-based architecture, this organisation gained greater flexibility to integrate data at scale. Data Factory's GUI made it easy for developers to visualise and orchestrate complex extract, load and transform processes.
Secure cloud data integration proved essential for rebranded application rollout. Data Factory provided the pipelines to validate orders against the manufacturer’s databases and generate certified PDFs. Despite differing backend systems, Azure Data Factory enabled consistent experiences for both subsidiaries.
Data Factory allowed this organisation to handle and validate the data that was being transferred from the respective subsidiaries’ individual databases. This meant that the data from the subsidiaries could be successfully transferred and accessed by users. The tool was especially useful for the organisation and its subsidiaries, who were dealing with large amounts of data pertaining to various chemical types.
Since adopting Data Factory, this organisation has accelerated their development cycles and data processing performance. The cloud service empowered faster app rebranding and more agility to adapt to changing business needs. This organisation continues leveraging Azure Data Factory for enhanced cross-company data flows and insights.
A truck manufacturing leg of a global automaker
Adopting AWS cloud technologies to improve agility in deployments and enhance the reliability and availability of services.
This automaker was facing an urgent deadline to separate their IT systems for an IPO. The organisation knew they needed a faster solution than building their own infrastructure to migrate to SAP S/4HANA. They chose AWS for its flexibility, scalability and cost benefits.
The organisation deployed S/4HANA on AWS. AWS provided the agility to adjust server sizing during the project, expanding from an initial 7-11 servers to the 17 needed. Post-launch, the manufacturer upgraded their production server in just 20 minutes when AWS released improved offerings.
The AWS cloud has provided major advantages for this automaker including giving them agility in deployment and ongoing operations, like near-instant upgrades. The AWS cloud environment has provided exceptional reliability and availability, with no service disruptions reported since migration. This robust uptime allows their manufacturing operations to continue unimpeded.
Additionally, the total cost of ownership with AWS is significantly lower compared to an on-premises model. The cloud's scalability let the automaker right-size capacity, avoiding overspending. This flexibility delivered an estimated 20-40% cost savings over alternative cloud providers.
The easy scalability of AWS allows the automaker to flex compute capacity on demand, aligning resources closely to evolving needs. This elasticity ensures efficiency and performance as business requirements change.
Legacy
Despite continual advancements in their industry, almost 75% of manufacturers are still holding onto their old legacy systems. Organisations often find themselves in a situation where they must deal with these ageing systems, which were once the backbone of operations but are now blocking innovation.
In manufacturing, the use of legacy systems brings unique challenges and risks. Precision and efficiency are crucial elements of any manufacturing organisation, which makes the presence of outdated systems particularly detrimental.
In this section:
- The risks of legacy systems
- Options for replacing legacy systems
- Approaches to modernising legacy systems
- Example case studies
Risks of Legacy Systems
The tangible maintenance costs associated with these outdated systems are just one area which they can negatively impact your organisation. While the financial aspect of maintaining legacy systems is a major concern, there are other costs if old technology is not appropriately managed or replaced.
This section looks at 5 other negative costs of legacy IT:
1. Reduced productivity
2. Demotivated employees
3. Increased security risks
4. Difficulty analysing data
5. A lack of innovation
1. Reduced productivity
Legacy software, such as outdated enterprise resource planning (ERP) systems or antiquated financial management software, presents numerous challenges for employees which can lead to impaired productivity long term.
Manufacturing relies on streamlined processes, and legacy software can hinder this by forcing employees to navigate through complex menus and perform manual data entry. The industry’s need for real-time data visibility and reporting makes reliance on legacy systems a significant bottleneck, impeding decision-making and efficiency. In manufacturing, even small productivity reductions can translate into substantial losses over time.
Moreover, legacy software may lack crucial features and integrations that are essential for streamlining processes and automating tasks. This causes employees to rely on manual workarounds and time-consuming, error-prone manual processes. The absence of real-time data visibility and reporting capabilities further hampers productivity, as employees struggle to access accurate and up-to-date information necessary for making informed decisions.
2. Demotivated employees
Employees who are using legacy systems are more likely to experience demotivation and frustration. Legacy systems often lack user-friendly interfaces, modern functionalities and efficient workflows.
These limitations can hinder employees' ability to perform their tasks effectively and efficiently, which can be highly frustrating and unmotivating. In the manufacturing sector, where precision and efficiency are crucial, demotivated employees can result in errors, delays, and suboptimal production processes.
3. Increased security risks
Manufacturing organisations handle sensitive data related to product designs, production processes and customer information. Legacy systems are often vulnerable due to the lack of timely security updates and modern security features.
In the UK, the percentage of organisations adhering to the policy of implementing security updates within 14 days has decreased over the past three years, dropping from 43% in 2021 to 31% in 2023. This decline highlights a concerning trend where organisations are failing to keep their systems updated and patched against emerging threats.
In an era of rising cyber threats, inadequate security measures can expose manufacturing companies to data breaches, intellectual property theft and operational disruptions, with potentially significant consequences.
4. Difficulty analysing data
Data is a key dependant for manufacturing organisations, as it enables them to carry out several key responsibilities, from optimising processes to allocating resources. Legacy systems make data analysis challenging due to outdated technology and decentralised data storage. Outdated technology and the lack of centralised data storage contribute to difficulties in obtaining accurate and relevant statistics for informed decision-making.
5. A lack of innovation
The manufacturing industry is evolving with advancements in AI, IoT and data analytics. Legacy systems, marked by their inflexibility, inhibit innovation and hinder the adoption of new technologies.
This lack of innovation can limit a manufacturer's ability to optimise processes and respond to changing market demands, which will ultimately affect their competitiveness and long-term viability in the industry.
Options for Replacing Legacy Systems
One of the primary considerations for any software development project is the choice between off-the-shelf product solutions and bespoke, custom-built systems. Each approach comes with its distinct advantages and disadvantages. Here 3 options are evaluated, to provide IT leaders with insights to make informed choices that best suit their specific requirements.
Option 1: Vanilla
Option 2: Bespoke
Option 3: Hybrid
Option 1: Vanilla
Also known as ‘out-of-the-box’ or ‘off-the-shelf’, a vanilla approach leverages software packages that are fit-for-purpose, implemented without any significant modifications. In manufacturing, this might be ready-made software like ERPs or MES implemented without customisation.
Adopting a vanilla approach came at a time when organisations were striving to keep up with competition. Instead of focusing on driving genuine business or customer improvements, a multitude of applications were implemented in a bid to be the most innovative organisation.
In the 1990s, vendors like SAP and Oracle pushed back on the continuous customisation of their systems, challenging customers to stick with the original code and processes. Instead of making hundreds of changes that required ongoing support, they believed their original, vanilla systems were better, lower risk and cheaper than intensive customisation efforts.
Benefits:
- Benefit in unravelling complexities created by convoluted process, workarounds and barriers by implementing a software package that has defined processes based on best practices.
- Benefit in having a single supplier dependency, as opposed to multiple providers in other approaches.
- Easy to implement if your processes are straightforward without the need for major organisational and process re-engineering.
The key to an effective use of a vanilla approach is making a specific match between your business processes and the off-the-shelf product. It is also important to note that organisations should prepare people, as well as processes, for this change, to ensure operations are kept to the new ways of working within the system.
Option 2: Bespoke
For manufacturers, custom-built software can provide more flexibility and innovation than off-the-shelf systems. Using an agile approach with prototypes and MVPs, bespoke solutions are designed around specific user needs and workflows.
Benefits:
- Optimised for your exact manufacturing processes and equipment
- Incorporate capabilities to support future growth and changes
- Tight integration between systems and data sources
- Intuitive for users with minimal training required
- Differentiates your operations from competitors
- You fully own the software and IP
Before engaging in a bespoke software project, it’s key to carry-out a build vs buy analysis to ask if there is already a software product that delivers the functions you need, for both current and future needs. These may include automating key processes and transactions, providing appropriate data handling, privacy and security functions, integrations and scalability, among others.
Once deciding a bespoke approach is the way forward to solve your specific business challenge, it’s important to define what it is going to solve and put in place measures to monitor success.
Key to driving success of your bespoke project will be the allocation of dedicated talent and internal resource to manage the project from analysis, throughout development, to completion. Including involving key user groups throughout the process to ensure a fit-for-purpose and intuitive solution.
Deciding which solution is right for your next technology upgrade will depend on the expertise within your team, resources available, your business goals and complexities, time frames and budget. There is no ‘one size fits all’, but in planning for technology projects, businesses should keep in mind how the solution will support both short- and long-term scalability plans, tie back to business strategies and provide the ability to react to growing and evolving business needs.
Option 3: Hybrid
Now that systems can be stored in the cloud, instead of being hosted in on-site servers, software is becoming more accessible and open to integrations through APIs. This has led to a increase in the adoption of a hybrid approach, consisting of a framework of decoupled systems to address specific business challenges.
This can be a combination of both off-the-shelf software products, customised applications and bespoke software. For example, implementing an ERP product to manage core business processes, integrated with additional bespoke applications such as customer portals or mobile applications to provide a competitive advantage.
Benefits:
- Benefit in resulting fit-for-purpose systems that work to your processes and workflows.
- Benefit in the ability to leverage legacy systems through the use of APIs to combine new systems and innovations with existing platforms.
- Benefit in the ability to roll out a product to manage core businesses processes relatively quickly without impacting current workflows, that you can then build on top of.
To ensure success and return on investment using a hybrid approach, you’ll need to clarify complex architecture and ensure you have sufficient teams to deliver.
You’ll need to define and empower project owners in order to drive engagement with the wider organisations and work collaboratively with supplier teams to drive project success.
Approaches to Modernising Legacy Systems
Facing a multitude of software options, manufacturing organisations operating within a competitive industry require a solution that aligns with their unique needs and production processes. Selecting the right approach for modernising legacy systems is important, as it can significantly impact the efficiency and competitiveness of manufacturing operations. Here are 3 approaches to modernising legacy systems:
Approach 1: Rehost
Approach 2: Refactor
Approach 3: Rebuild
Approach 1: Rehost
The process of rehosting your applications involves migrating them to a more modern infrastructure without modifying their code or changing their business logic.
In these scenarios, legacy technology will usually be shifted to a modern app environment. This approach is the least invasive method for modernising your legacy systems.
Examples of this approach include:
- Migrating an application from one cloud environment to AWS
- Data migration from an on-premises server to the cloud
- Upgrading an older Amazon Elastic Compute Cloud (EC2) instance
As these examples show, the complexity of rehosting your legacy systems can vary. Hosting your old application in a newer environment is generally less complex than migrating your data from an on-premises server.
Rehosting remains a relatively low-risk approach for businesses who are looking to modernise their legacy systems. Rehosting your legacy systems means that businesses access the benefits of modern technologies like the cloud without making major changes to application code. A modern hosting solution also solves the issue of expensive maintenance by replacing legacy technology.
In the case of on-premises servers, for instance, there is a need for an air-conditioned server room as well as staff costs for the administrative work which, in turn, includes patching and virus scanning of the operating system.
This approach is advised if your legacy applications are working to an adequate standard, but the infrastructure behind them is outdated. Legacy infrastructure can lead to problems around costs and security.
For example, older systems are more likely to be infected with malware. Patching these systems constantly is a frustrating expense for businesses, made even worse in those cases where no patches are available. A rehosting approach is more often used as a temporary approach while a new application is being developed. In other cases, it can be the first step in a larger rebuild process.
Approach 2: Refactor
A refactoring approach involves changing parts of a legacy system to optimise code. Refactoring is a more affordable way to get access to modern technology features without making significant changes to a legacy system.
This process involves changes on the backend, such as reducing redundancies or errors, without significantly altering the UI or functionality. The external behaviour of the application will, therefore, remain relatively unchanged. Refactoring is less invasive than rewriting, where developers would create new code and implement completely new functionality.
Here are some scenarios where refactoring might be appropriate:
- You want to make improvements to your system, but the existing infrastructure makes it very difficult to execute.
- You don’t want to change the functionality of your existing system.
- You need to bring a codebase up to a supported version of a framework (e.g. .NET).
- Newer, more efficient production methods have been adopted on the factory floor, but the inventory and scheduling systems are still tailored to older workflows. Refactoring could update these systems to match the new processes.
A key advantage of refactoring rather than completely rewriting systems is that it enables incremental improvements without major disruptions. Manufacturers can modernise systems gradually while minimising downtime on the production floor.
Through targeted code changes, manufacturers can enhance integration between disjointed systems from mergers and acquisitions, comply with new regulations, and adapt to newer manufacturing methods.
However, refactoring has limitations. It focuses on optimising existing functionality rather than adding new features. And comprehensive testing is critical to ensure code changes don't introduce new defects.
When considering refactoring, manufacturers should thoroughly evaluate current processes and systems. Other options like rewriting or rehosting legacy software may be more suitable depending on specific needs and limitations. However, for many, refactoring provides a cost-effective way to boost the quality and performance of essential manufacturing systems.
It is also advised that you do not carry out refactoring without a comprehensive regression test. These tests will verify if the code change brings with it any issues into the existing functionality. Automated tests are a huge benefit here because, once created, automated tests can be repeatedly run to detect any defects.
Approach 3: Rebuild
Completely rebuilding legacy systems is the most extensive approach for modernising outdated manufacturing software and hardware. The goal, here, is to develop new, cloud-native systems optimised for current manufacturing needs rather than trying to update rigid, legacy platforms.
Rebuilding requires extensive planning and buy-in from stakeholders, as it often means re-examining processes and adopting new ways of working. However, it enables manufacturers to fully leverage the latest technologies for improved quality, efficiency and flexibility.
Rebuilding typically involves rewriting software components using modern languages and architectural approaches like microservices. This facilitates rapid deployments, better data integration and scalability. New hardware and automation can also be incorporated to optimise production flows.
Manufacturers may consider complete rebuilds when:
- Legacy systems are too costly to maintain and license
- Existing platforms cannot achieve required output or quality
- Core technologies are obsolete and replacement parts are unavailable
The main challenge is balancing significant change with current manufacturing requirements. However, done right, rebuilding gives manufacturers an opportunity to completely rethink systems and processes to meet strategic objectives.
Data analytics and IoT can be tightly integrated to enable smart manufacturing, and emerging technologies like AI and robotics can be tested and implemented faster.
While full rebuilds require major investments, they allow manufacturers to innovate with agility and optimise operations for long-term success. Carefully scoping projects helps balance costs with high-value impacts on productivity and competitiveness.
Example Case Studies
A global industrial manufacturer
Rebuilding disparate legacy systems into one integrated, centralised product suite to improve user experience, system management and support growth and change across the business.
This industrial manufacturer was relying on disparate legacy systems that lacked central control and knowledge sharing between business functions. Manual spreadsheet processes were insufficient for the organisation’s extensive data needs.
The organisation determined that a comprehensive overhaul of their legacy systems would maximise the efficiency and longevity of their new solutions, deciding to adopt a rebuild approach. Initial data was imported via SQL, while database backups were provided to ensure security. Stringent procedures further safeguarded data during migration.
The manufacturer developed various complex systems as part of the legacy modernisation project:
1. A knowledge database: Used to track and maintain information around materials, operating viscosity, operating temperatures and operating pressures used in the design of sealing solutions.
2. An automated quotation platform: Used to develop complex product configuration for sealing solutions across oil platforms, chemical plants and water treatment plants, plus other areas.
3. Site survey application: Used to track the setup of various sealing solutions across locations, departments, sites, plants and countries, as well as track maintenance information in real time so it can predict component replacement before they fail at the end of their life cycle.
The platform was deployed to on-premises servers using continuous deployment pipelines for consistent, reliable production deployments. This gives the organisation full control over their data. Modernising legacy systems overall simplified system management and user experience while being robust enough to support £170m+ annual sales and deliver real-time visibility & reporting across global operations.
Two leading manufacturing innovation organisations
Modernising legacy systems and processes to achieve real-time collaboration and visibility across projects, operations and people.
Two leading manufacturing innovation organisations sought to modernise their legacy workshop programme which relied on inefficient manual and paper-based processes. These workshops are held for clients to discuss areas for improvement and propose projects to help them achieve their goals.
The solution was an interactive project planning portal used exclusively for the workshops, that could enable real-time collaboration and visibility into project ideas and plans.
This bespoke legacy modernisation project eliminated the organisation's cumbersome paper-based processes that could take up to seven days to coordinate. Now workshop data flows seamlessly into integrated visualisations and diagrams. Participants can collaboratively map priorities, share ideas and contribute to project plans in real-time from connected devices.
The portal centralises and digitises the entire workshop experience, from the initial ideas to tracking project progress against defined visions. It provides a streamlined, interactive roadmapping process for clients and enhances the organisation's overall service offerings.
Key results of this legacy modernisation included reducing project management time from seven days to just one. It also eliminated the wasted work hours that were previously spent on manual paperwork. Within months, both organisations had already generated new business opportunities with the portal.
AI and Machine Learning
The proliferation of internet of things (IoT) sensors and smart factory automation has enabled manufacturers to generate vast amounts of process data. Research shows that manufacturers currently produce over 1,800 petabytes of data annually, exceeding the data volume of banking, retail and telecommunications.
However, to derive value from this high-volume data, manufacturers need advanced analytics powered by artificial intelligence (AI) and machine learning algorithms. By applying AI to analyse real-time production data, manufacturers can uncover optimisation opportunities not previously visible.
One application is using insights from AI to proactively predict equipment failures before they occur. Predictive maintenance involves machine learning models continuously monitoring equipment sensor data and identifying patterns predictive of failure. Manufacturers leveraging predictive maintenance capabilities can minimise unplanned downtime and improve asset lifecycle management. Other high potential use cases for AI in manufacturing include identifying production anomalies, enhancing quality control and optimising supply chain and logistics.
While manufacturers have long relied on analytics, AI enables a step change improvement in extracting insights from exponentially growing data volumes. By implementing machine learning across the manufacturing life cycle, executives can drive greater efficiency, sustainability and competitiveness.
In this section:
- How to get started
- Approaches to adopting AI and machine learning
- Example case studies
How to Get Started
Organisations have various factors to consider when beginning AI and machine learning projects, from defining the processes, people and data that fall within the scope to choosing the methods and technology to implement. In this section we will outline three key considerations in detail.
- What type of data are you working with?
- Are you gaining insights from data or generating data?
- What model should you use?
Data Types
What type of data are you working with?
Are you working with financial data, user activity, volumes of text, images or something else? Is your data structured or unstructured? For example, your organisation may want to analyse online customer behaviour to inform marketing strategies. The data involved would consist of structured data such as user demographics, browsing preferences and purchase records. In this scenario a model could be used to capture preferences in future behaviour.
Alternatively, if you want to visually identify stock, then your data will be images. Many image classifiers have been pre-trained, where a model that has already been trained on a dataset. Using pre-trained models can allow organisations to begin quickly leveraging AI technology without having to invest in training data and models from scratch. Pre-trained models like those offered in Azure Custom Vision and AWS Rekognition provide a strong foundation for these scenarios, with pre-trained models for image classification and object detection, specifically.
Also consider the data that you would receive from your solution; how will you evaluate the output? If you decide to use a language model to process and generate text (e.g. a chatbot), then it is important to consider the challenges that come with evaluating its responses. Large language models can be difficult to test because their outputs are subjective; how would you define an ideal response?
There are different strategies for evaluating generative language models and each one will likely be suited to a different use case. You may want to evaluate the truthfulness of the model's responses (i.e. how accurate are its responses by real-world factual comparisons) or how grammatically correct its responses are. For translation solutions, you are more likely to measure metrics such as the Translation Edit Rate (TER), that is, how many edits must be made to get the generated output in line with the reference translation.
Language libraries like LangChain provide features for evaluating the responses according to relevance, accuracy, fluency and specificity, as well as giving you the flexibility to define your own criteria for evaluation via the LangChain API.
Data Outputs
Are you gaining insights from data or generating data?
Clarify whether your intended solution would process and analyse existing data or generate new content. For cases where you want to identify patterns or predict future behaviour, a model that processes data will be well-suited. Examples could include a solution to analyse existing customer data, from which trends can be identified and form predictions.
Data generation solutions, on the other hand, are used to create data that did not previously exist. This new data could take the form of synthetic data that can then be used to train and test machine learning models, or even new creative content, such as text or images.
There is also the option of using a solution that is capable of both processing and generating data. This type of solution can be advantageous in cases where you want your model to learn from its experiences and the data that it is processing. An e-commerce organisation may train a model on a large data set of user behaviour to learn about customers interests. Once this training is completed, the model could then be used to generate new recommendations for users.
Model Selection
What model should you use?
The core component at the centre of a machine learning project is a trained model, which in the simplest terms is a software program that, once given sufficient training data, can identify patterns and make predictions. Your final consideration, therefore, should be how you will access a model for your AI/ML project. In the following sections we will look at two popular approaches for accessing a machine learning model.
With a better understanding of the key considerations for getting started with AI projects, your organisation will be able to evaluate these approaches in line with your intended data area and output.
Approaches to Leveraging AI and Machine Learning
Approach 1: Cloud Services
AI cloud services enable organisations to rapidly adopt and leverage AI technology by providing pre-built models, APIs and infrastructure. Because of the wide range of pre-built models that cloud services offer, it can be useful for organisations to first think if they can achieve their objectives using a cloud service that already exists.

Azure, Google Cloud and AWS provide pre-built, pre-trained models for use cases such as sentiment analysis, image detection and anomaly detection, plus many others. These offerings allow organisations to accelerate their time to market and validate prototypes without an expensive business case.
Where previously machine learning projects have required specialised expertise and substantial resources, AI cloud services enable organisations to quickly develop AI solutions for a range of applications.
In this section:
- How to get started
- Benefits
- Considerations
How to get started
1. Choose a cloud service provider: Evaluate cloud service providers Azure, Google Cloud and AWS to determine which platform aligns best with your project requirements and budget. Your organisation may already use Microsoft, Google or Amazon products elsewhere and, therefore, choose to align this choice with your existing stack.
2. Select the relevant services: Identify the specific AI cloud services that match the needs of your manufacturing project. For example, if you need to optimise production, look at Azure Cognitive Services for Anomaly Detector or Amazon Lookout for Equipment. To automate quality control, you could use Azure Form Recognizer or Amazon Textract. For forecasting demand, options include Azure Cognitive Services Forecast or Amazon Forecast.
3. Preparing and aggregating data: This may involve aggregating and structuring the data to ensure it is suitable for the chosen service. For a manufacturing predictive maintenance service like Azure Machine Learning or AWS SageMaker, an important practice is collecting sensor data that represents normal and abnormal equipment operation. This data should capture the range of machine states and failure modes you want to detect. If you are training a model to optimise manufacturing quality control, you may need images or video representing good and defective products. The data preparation process ensures you have sufficient labelled examples to train an accurate machine learning model.
4. Data cleansing: It is important to clean the data to eliminate any inconsistencies or irrelevant information that could impact the analysis. For services involving natural language processing and understanding, preprocessing and standardising text data is important. This process might involve removing punctuation, converting text to lowercase, and addressing common abbreviations.
5. Build and train your model: Use the cloud service’s tools and APIs to build and train your model. Certain services provide the choice of selecting a pre-trained model. Azure Anomaly Detector, for example, provides pre-built machine learning models to detect anomalies in time series data. You can feed in your manufacturing sensor data, and it will identify outliers and unexpected fluctuations without needing to train a model yourself. This can help to quickly surface equipment issues for investigation.
6. Test and evaluate: Test your AI model using sample data to ensure it is performing as expected. Evaluate its accuracy and performance. This could be done by comparing the model's predictions against known ground truth labels or by using validation datasets.
Benefits
- Scalability: These services can be scaled up or down according to the resource needs, a particular advantage for organisations who may need to handle or generate large amounts of data.
- Reduced time and cost to set up: Many of the models provided in these services come pre-trained and pre-built, which saves time and effort setting up AI capabilities from scratch.
- Rapid prototyping: Being able to get started quicker with AI cloud services enables rapid prototyping and experimentation with different AI techniques without investing heavily upfront in research and infrastructure. With these services, manufacturers can quickly test proof-of-concept projects to evaluate the viability of AI for different applications.
- Lower entry point: Users do not require extensive technical expertise to use these services. Azure, Google Cloud and AWS provide intuitive interfaces and tools to further simplify the process of creating AI solutions.
- Security: Users are afforded the security features of leading cloud providers Azure, Google Cloud and AWS, such as data encryption, access control and integrations for automating security tasks. Azure has the most certifications of any cloud provider.
Considerations
- Level of customisation: AI cloud services do not provide the same customisation as building your own models. For common tasks like image classification, pre-trained models often work well. However, for complex manufacturing challenges like predicting equipment failure or optimising production, these cloud services may not capture the nuances of your specific environment. If you need to finely tune the model architecture, features and training process for your use case, developing a custom model could lead to better performance.
- Costing approach: Azure, Google Cloud and AWS offer their services through a pay-as-you-go model. While this is beneficial in that it enables you to only pay for what they need, organisations should carefully manage their usage to avoid unexpected costs. One way this consideration can be addressed is by utilising cost management tools such as Microsoft Cost Management or AWS Cloud Financial Management. Cost optimisation strategies, such as using reserved instances or spot instances for non-time sensitive workloads, can also be helpful for reducing unexpected costs.
Approach 2: Defining Your Own Model
In cases where you want more control over the development and training of your own model, it can be useful to leverage a machine learning framework like TensorFlow or PyTorch. These frameworks offer libraries and tools to help develop machine learning models.

Building a machine learning model generally refers to the entire process of creating a model from scratch, including selecting an appropriate algorithm or architecture, defining the model's structure and implementation.
Defining a model, alternatively, will more likely involve working with a model from a library or using a framework that provides predefined architectures. Which approach you take will be determined by your organisation's use case, resources and the granularity with which you want to create a model. Building from scratch affords even greater customisation and control over your model but will come with higher financial and computational costs.
In this section:
- How to get started
- Benefits
- Considerations
How to get started
1. Decide between using an existing model or developing your own: Consider whether an existing model already addresses your problem. PyTorch, TensorFlow and Scikit-learn offer functionality that can be leveraged for everything from data pre-processing and feature engineering to model training and evaluation. The versatility and power of these frameworks makes them a very viable option if you are choosing to configure or develop your own model.
2. Select a framework: Scikit-learn is a powerful framework for accessing pre-built models or developing custom models across a range of algorithms including classification, regression and clustering algorithms.
Working specifically within the area of neural networks, it is possible to develop custom deep learning algorithms using frameworks such PyTorch or Tensorflow, developed and used by Meta and Google respectively. These deep learning models can then be used to power solutions such as virtual assistants and speech recognition systems. Both these frameworks are built upon the concept of tensors, which can simply be thought of as multi-dimensional arrays.
Both are mature and stable frameworks, each with their strengths and weaknesses. For example, being heavily used in research areas, PyTorch can provide more access to state-of-the-art models, whereas TensorFlow in certain scenarios can provide increased performance due to its ability to take advantage of GPUs and other specialised processors.
For organisations approaching this with experience in the Microsoft technology stack, ML.NET is also an option with seamless integration capabilities. However, compared to other development frameworks, ML.NET has a more limited set of pre-built models and algorithms available.
3. Aggregating, cleansing and preparing data: This involves collecting all the data that you will use for training your model. Once this data is collected, it will need to be prepared for training, with processes like cleansing being important in getting the data into a format which the data can understand and learn from.
For example, sensor data would need accurate timestamps and labels indicating whether the equipment was operating normally or exhibiting signs of failure during that time. Proper data preparation is crucial so the model can learn to make accurate predictions.
4. Defining your model: Developing and tuning your model is a crucial step in this process and goes beyond simply defining the structure and design of the model. This will require choosing the appropriate algorithms and layers to make your model as effective as possible.
When it comes to selecting parameters, be sure to carefully consider their impact on the model’s performance and ability to generalise. Experimentation and iteration are key in finding the optimal configuration for your specific problem.
In this aspect, PyTorch and TensorFlow are very useful frameworks in that they give you access to a variety of libraries and tools that make it easier to, for example, define neural networks and apply optimisation techniques. Frameworks like Scikit-learn also offer a diverse set of algorithms for traditional machine learning tasks.
5. Training your model: This is where you provide your model with the data it needs to learn. Keep in mind that how long this will take vary greatly, ranging from minutes to months, depending on the complexity of your model and the size of your dataset. This step can be the most time and resource intensive, so it is a good idea to capture the usage metrics of this stage before deploying your model to any production environments.
6. Evaluate your model: Your model will need to be evaluated on a held-out dataset after it has been trained. By doing this, you can determine how well the model generalises unseen data.
7. Deploy your model: When you are satisfied with the model's performance, you can deploy it in production, which could be anything from hosting the model with API access to embedding the model within a cloud-based web application.
At this stage, it is important to consider the type of inference required for your specific use case: real-time or batch inference. Batch inference processes large batches of data periodically. This approach can support complex models and produce results with latency.
These factors make it suitable for situations where you need to produce large batches without requiring immediate results. If you are working in scenarios such as data analysis or generating reports where the focus is on comprehensive analysis, rather than real-time decision-making, then batch inference can be a useful solution.
Real-time inference, alternatively, delivers a small number of inferences instantly. Fraud detection and recommendation systems are two well-suited use cases for real-time inference because they require instant predictions to respond to dynamic situations. One caveat when taking this approach is latency constraint. Real-time inference is less suitable for deploying complex models that require extensive computational resources or have longer processing times.
Benefits
- Control: When you define or build your own model, you take charge of its entire lifecycle. This control allows you to continuously update and enhance the model as new data becomes available. You are not dependent on external providers or constrained by rigid frameworks if you are building your model from scratch.
- Understanding your model: The models used in AI cloud services are sometimes referred to as "black boxes" because they lack transparency. However, when you define your own model, you gain a deeper understanding of its inner workings and can interpret its behaviour more accurately. This level of interpretability becomes especially valuable in a manufacturing setting, where you need to trust and verify the system’s outputs.
- Flexibility and customisation: Machine learning frameworks provide a variety of algorithms and customisation options that enable developers to tailor models to specific project requirements and data characteristics. TensorFlow, for example, offers a high-level API called Keras that enables developers to build and customise deep learning neural networks.
Considerations
- Expertise required: Defining or building your own model requires a greater understanding of machine learning concepts, as well as the underlying mathematics that support them. An understanding of different algorithms and optimisation techniques can help with important processes such as defining your model and data preparation. However, organisations can still leverage pre-built models with this approach which helps to reduce the expertise required.
- Resource intensive: It is important to have access to sufficient computational resources and ample storage capacity to handle the data required for creating your own model. When it comes to hosting your model, the cloud offers scalable and flexible resources that can handle the computational requirements of training and deploying models.
Read more about how to implement AI and machine learning into your organisation in our guide: An IT Leaders Guide to AI and Machine Learning
Example Case Studies
A global medical device manufacturer
Planning optimisation - Leveraging combinatorial optimisation models to solve task scheduling problems
A leading medical device manufacturer was seeking to optimise its sterilisation operations. The organisation operates sterilisation facilities globally in over 100 countries to sanitise medical products and instruments for healthcare providers.
Leveraging machine learning framework ML.NET, an application was created to accurately predict the dose range for products undergoing sterilisation. The prototype, trained on historical data, leveraged machine learning algorithms within ML.NET to predict the level of sterilisation required for products prior to product loading.
All results provided by the dosage predictor were made available to scheduling administrators who could then make informed decisions based on the predicted dose range. The tool empowered users to assess the probability of failure, for instance, by indicating that processing the solution at a certain speed had a 90% chance of failure.
The system was able to calculate the probability of achieving the desired dose range (e.g. 26.2 – 31.8kGv) for a given set of processing speeds. This flexibility empowered the manufacturer to optimise their scheduling and dosage processes, while ensuring compliance with contractual obligations.
The dosage predictor not only enhanced existing processes but also provided scheduling administrators with data-driven insights to optimise their decision-making. The project highlighted the power of machine learning frameworks like ML.NET to create custom machine learning solutions quickly.
A global automaker
Predictive analysis - Leveraging algorithms for predictive maintenance to prevent and minimise downtime
A major global automaker has been leveraging artificial intelligence to optimise quality control and improve efficiency across its production facilities since 2018. The company uses machine learning algorithms for predictive analysis on equipment to minimise downtime and enable preventative repairs. By analysing data from machinery, the automaker can forecast maintenance needs before breakdowns occur.
Similar AI models are applied across the assembly line to identify potential bottlenecks. The algorithms help ensure streamlined workflows and that the right components are available by predicting vehicle demand and availability. The company's dedicated data and AI team facilitates rapid adoption of these AI capabilities throughout its manufacturing network.
One example is the use of automated image recognition during the painting process for a luxury vehicle model. AI algorithms monitor over 160 features while vehicles move through the painting station, predicting paint quality with high accuracy.
This allows rapid adjustments if any imperfections are detected. In the pressing station, neural networks analyse images to differentiate real metal sheet defects from pseudo-defects like oil residues, further streamlining processes and reducing unnecessary scrapping.
Their data & AI initiative facilitates seamless knowledge and technology transfer within the company, fostering rapid adoption of AI capabilities. With over 600 use cases, the organisation’s portfolio demonstrates a commitment to data-driven decision-making and innovation.
Download

